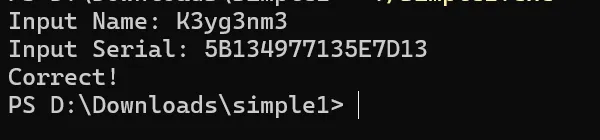
simple1
先输入Name,sprintf将Name与v7异或后存在Buffer
之后输入Serial,比较Serial与Buffer。
已知Serial为5B134977135E7D13
经过测试发现v7并不是IDA分析给出的 qmemcpy(v7, ” 0”, sizeof(v7));
可以根据输入反推出v7为v7=[16,32,48]。
然后得到正确name
simple2
看输出是RC3加密,其中s[i] != (char)(v8[i % v6 - 8] ^ v8[i])
这个ida又分析错了,实际上是(v7[i % v6]) ^ (v8[i])
附上解密代码
v6 = 7
v8 = [58, 34, 65, 76, 95, 82, 84, 94, 76, 42,
46, 63, 43, 54, 47, 52, 54]
v7 = [104, 97, 114, 97, 109, 98, 101]
re = [0]*len(v8)
for i in range(len(v8)):
re[i] =(v7[i % v6]) ^ (v8[i])
for i in range(len(v8)):
print(chr(re[i]),end="")simple3
py逆向,使用pylingual无法反编译,但是使用uncompyle6就可以顺利反编译。
# uncompyle6 version 3.9.2
# Python bytecode version base 2.7 (62211)
# Decompiled from: Python 3.12.4 (tags/v3.12.4:8e8a4ba, Jun 6 2024, 19:30:16) [MSC v.1940 64 bit (AMD64)]
# Embedded file name: 1.py
# Compiled at: 2017-06-03 10:20:43
import base64
def encode(message):
s = ''
for i in message:
x = ord(i) ^ 32
x = x + 16
s += chr(x)
return base64.b64encode(s)
correct = 'XlNkVmtUI1MgXWBZXCFeKY+AaXNt'
flag = ''
print 'Input flag:'
flag = raw_input()
if encode(flag) == correct:
print 'correct'
else:
print 'wrong'
# okay decompiling simple3.pyc很容易写出解密脚本
import base64
a = "XlNkVmtUI1MgXWBZXCFeKY+AaXNt"
a = list(base64.b64decode(a))
for i in a:
i = i-16
i^=32
print(chr(i),end="")simple4
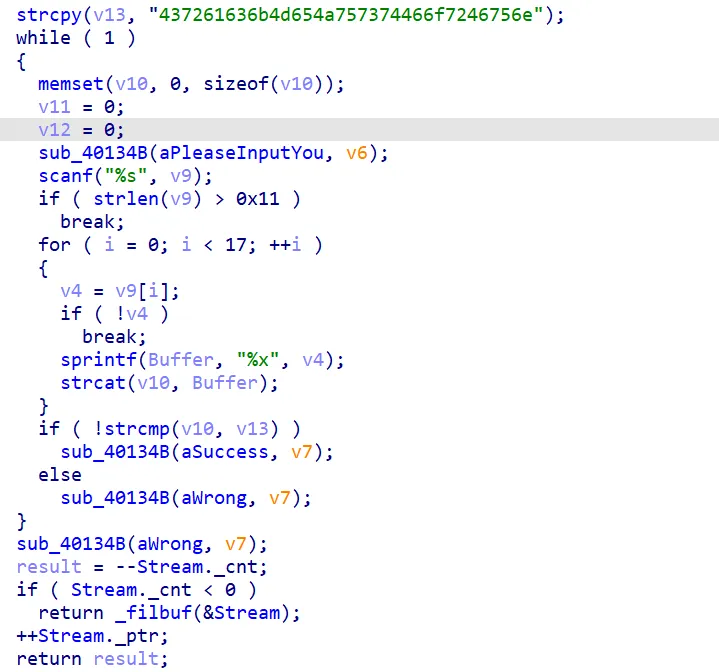
a = bytes.fromhex("437261636b4d654a757374466f7246756e")
print(a)simple5
for ( i = 0; i < v5; ++i )
{
Str[i] ^= v6;
v6 = Str[i];
if ( Str[i] != arr[i] )
fun();
}解密脚本
a = [0x55, 0x0F, 0x5E, 0x25, 0x6D, 0x2C, 0x7A, 0x3F, 0x60, 0x21,
0x7E, 0x39, 0x76, 0x39, 0x7D, 0x22, 0x76, 0x3F, 0x72, 0x37,
0x68, 0x49, 0x34]
b= [0]*23
a1= 19
for i in range(len(a)):
b[i]=a[i] ^ a1
a1 = a[i]
print(chr(b[i]),end="")simple6
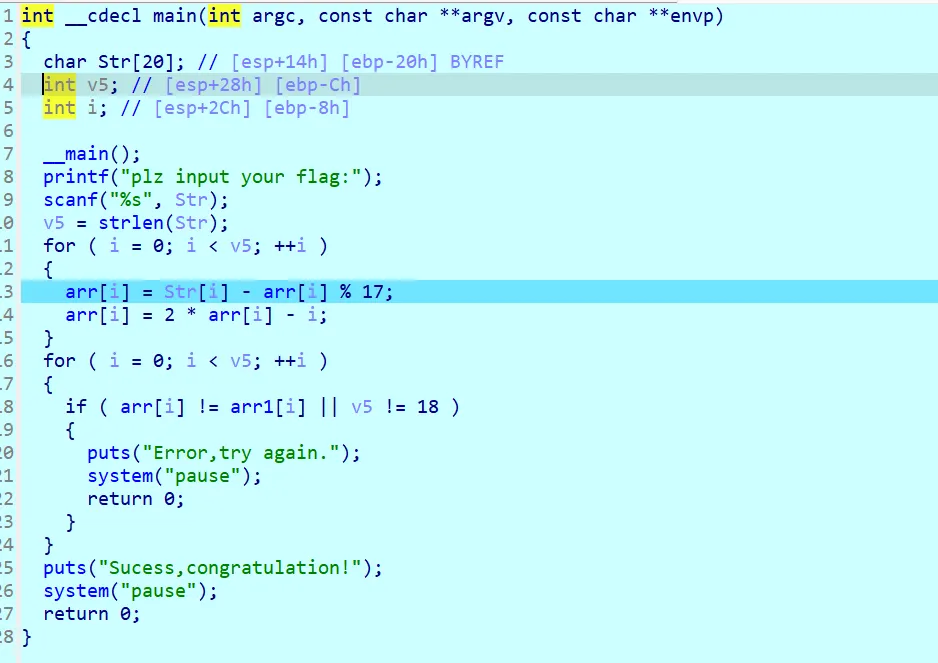
写一个爆破脚本:
arr = [23, 22, 26, 26, 25, 25, 25, 26, 27, 28, 30, 30, 29, 30, 32, 32, 33, 32 ]
arr1 = [128, 169, 142, 225, 136, 189, 212, 165, 136, 191, 198, 153, 118, 171, 150, 175, 18, 203]
def baopo(arri,arr1i,i):
for c in range(33, 127):
dd = arri
arri = c - arri % 17
arri = 2 * arri - i
if arri == arr1i:
print(chr(c), end='')
if arri != arr1i:
arri=dd
for i in range(len(arr)):
baopo(arr[i], arr1[i], i)
print()部分字符可能出现多解,能看出来正确字符是哪个
最后答案FZQ{Niu_Rou_Mian!}
simple7
分析代码:
v3 = (unsigned __int8)(flag[i] >> 7) >> 4;
a = (char)(((v3 + (flag[i] >> 4)) & 0xF) - v3);
v4 = (unsigned int)((16 * flag[i]) >> 31) >> 28;
b = (((_BYTE)v4 + (unsigned __int8)((16 * flag[i]) >> 4)) & 0xF) - v4;
c = 22 * a + 12 * b;v3肯定是0
a是最高4位
b是最低4位
c是一个方程。遍历求解
附上解密脚本:
arr = [160, 230, 122, 286, 230, 144, 290, 208, 240, 144, 300, 216, 290, 244, 240, 100, 256, 310]
for c in arr: # 已知的c值
for H in range(16):
for L in range(16):
if 22 * H + 12 * L == c:
flag_i = (H << 4) | L
print(chr(flag_i),end='')
print()simple8
走迷宫问题,经典套路
simple9
# uncompyle6 version 3.9.2
# Python bytecode version base 2.7 (62211)
# Decompiled from: Python 3.12.4 (tags/v3.12.4:8e8a4ba, Jun 6 2024, 19:30:16) [MSC v.1940 64 bit (AMD64)]
# Embedded file name: secend.py
# Compiled at: 2019-02-01 21:18:58
print "Welcome to Processor's Python Classroom Part 2!\n"
print "Now let's start the origin of Python!\n"
print 'Plz Input Your Flag:\n'
enc = raw_input()
len = len(enc)
enc1 = []
enc2 = ''
aaa = 'ioOavquaDb}x2ha4[~ifqZaujQ#'
for i in range(len):
if i % 2 == 0:
enc1.append(chr(ord(enc[i]) + 1))
else:
enc1.append(chr(ord(enc[i]) + 2))
s1 = []
for x in range(3):
for i in range(len):
if (i + x) % 3 == 0:
s1.append(enc1[i])
enc2 = enc2.join(s1)
if enc2 in aaa:
print "You 're Right!"
else:
print "You're Wrong!"
exit(0)
# okay decompiling simple9.pyc还是pyc逆向,先是奇偶不同操作,然后打乱顺序生成s1,最后加密完是:ioOavquaDb}x2ha4[~ifqZaujQ#
解密脚本如下:
enc2 = "ioOavquaDb}x2ha4[~ifqZaujQ#"
n = len(enc2)
idx = 0
enc1=[0]*n
re = []
for i in range(0, n, 3):
enc1[i] = enc2[idx]
idx += 1
for i in range(2, n, 3):
enc1[i] = enc2[idx]
idx += 1
for i in range(1, n, 3):
enc1[i] = enc2[idx]
idx += 1
for i in range(n):
if i%2==0:
re.append(chr(ord(enc1[i])-1))
else:
re.append(chr(ord(enc1[i])-2))
print(''.join(re))
#hgame{Now_Y0u_got_th3_PYC!}simple15
第一步很简单的加密,但是也没有太大帮助。

也就是命令行传入flag.txt,之后从flag.txt读取数据。
之后也很简单
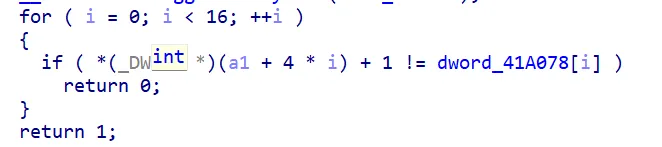
从这里读取数据减一换成hex就是,
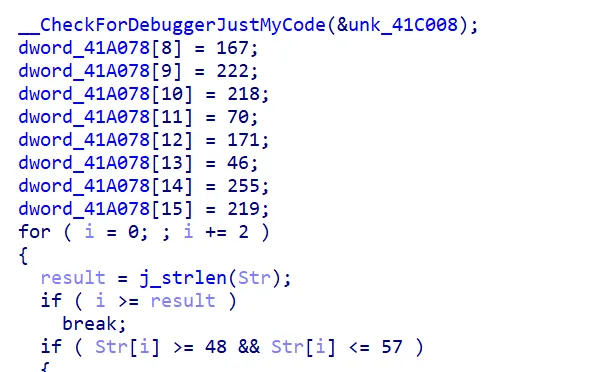
注意一下这里也定义了数组内容。
Geesec{4fc5f0e3e2e199a0a6ddd945aa2dfeda}
Thanks for reading!